Free
Trial

Localize and Extract Key Data from Specified Region using OCR
Enterprise-Ready Text Detection and Recognition SDK
Dynamsoft Label Recognizer SDK uses OCR to read alphanumeric characters and standard symbols from images with varying background colours, fonts, or text sizes. Unlike traditional OCR, our label recognizer is designed to parse text that does not follow natural language rules. Dynamsoft Label Recognizer can be customized for specific character and symbol patterns such as ID cards, inventory labels, price tags, automotive VIN codes and license plates.
Sparse and short text, sometimes random numbers and chars for machines to read
Dense text, mostly natural language
Images such as pricing labels, ID cards, tags
Full-page documents
Extract meaningful data that are structured and semi-structured
Convert image to text for archive and search
Use reference regions to locate the meaningful text, such as, below a barcode, or, within a yellow rectangle
All texts in the doc are of interest
Customized regex to ensure accuracy
Grammatically interprets and analyzes phrases by using a dictionary to improve accuracy
-

Specify an area to OCR texts using a reference region
-

Sophisticated image pre-processing algorithms
-
Use a regular expression to improve accuracy and robustness
-

Stitch content results from neighbouring video frames

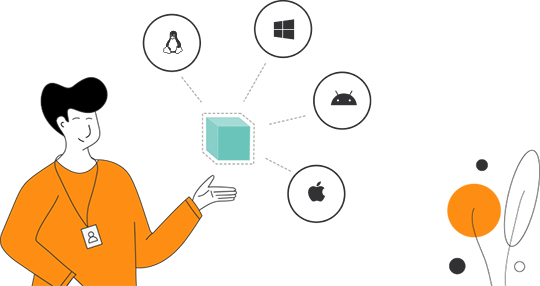
OS and Programming Language Support
Dynamsoft Label Recognizer SDK supports major platforms (Windows, Linux, iOS, and Android) with its C/C++, C#, Objective-C/Swift, and Java interfaces.