


Build a Web App to OCR Scanned Documents with Tesseract.js and Dynamic Web TWAIN
Paper documents are still ubiquitous in our everyday work, like invoices, checks and printed books. It takes effort to manage them.
With Dynamic Web TWAIN, we can build a web application to scan documents from document scanners. But further steps are required to better manage the documents and OCR is an important part of the process. Here is a list of what OCR can help with the document managing process:
- Save time for manual data entry.
- Save disk space by digitizing the document images.
- Full-text search can be used to find useful data easily.
- Use the text for further editing, translating, etc.
In this article, we are going to talk about how to use Tesseract.js to run OCR on documents scanned with Dynamic Web TWAIN.
What you’ll build: A browser-based web app that scans paper documents (or loads PDFs/images) using Dynamic Web TWAIN, then extracts text from each page with Tesseract.js — with batch OCR and a one-click text download.
Key Takeaways
- Tesseract.js provides free, client-side OCR in the browser — no server-side processing is required.
- Dynamic Web TWAIN connects to TWAIN/ICA/SANE scanners directly from JavaScript, enabling document acquisition in any modern browser.
- Batch OCR lets you process multi-page scans in a single pass and download all extracted text as a file.
- OCR accuracy depends heavily on scan quality — 200+ DPI, deskewed, high-contrast images produce the best results.
Common Developer Questions
How do I run OCR on scanned documents in the browser using JavaScript?
Acquire or load the document pages into Dynamic Web TWAIN first, then pass the selected image data into Tesseract.js and display the returned text in the browser. The same setup can run on one page at a time or across a full multi-page batch.
How do I combine Tesseract.js with a document scanner SDK for batch text extraction?
Use Dynamic Web TWAIN for acquisition, page buffering, and image editing, then iterate through each buffered page and feed it into Tesseract.js for recognition. That division of work gives the app both scanner connectivity and browser-side OCR without needing a backend service.
How can I improve Tesseract.js OCR accuracy on scanned PDFs and images?
Tesseract performs best on clean, high-contrast pages at roughly 200 DPI or above, so document cleanup matters before OCR begins. In this workflow, Dynamic Web TWAIN can deskew, crop, and adjust brightness or contrast before the page is handed to Tesseract.js, which improves the extracted text noticeably on noisy scans.
Prerequisites
- Node.js and npm installed
- A TWAIN-compatible document scanner (or use the file-loading feature to test with local images/PDFs)
- Get a 30-day free trial license for Dynamic Web TWAIN
Step 1: Create a New Webpack Project
Clone a webpack starter project as the template for starting a new project:
git clone https://github.com/wbkd/webpack-starter
Step 2: Install Dynamic Web TWAIN and Tesseract.js
-
Install Dynamic Web TWAIN.
npm install dwtIn addition, we need to copy the resources of Dynamic Web TWAIN to the public folder.
-
Install
ncp.npm install --save-dev ncp -
Modify
package.jsonto copy the resources for the build and start commands."scripts": { "lint": "npm run lint:styles; npm run lint:scripts", "lint:styles": "stylelint src", "lint:scripts": "eslint src", - "build": "cross-env NODE_ENV=production webpack --config webpack/webpack.config.prod.js", - "start": "webpack serve --config webpack/webpack.config.dev.js" + "build": "ncp node_modules/dwt/dist public/dwt-resources && cross-env NODE_ENV=production webpack --config webpack/webpack.config.prod.js", + "start": "ncp node_modules/dwt/dist public/dwt-resources && webpack serve --config webpack/webpack.config.dev.js" }, -
Modify
webpack.common.jsto copy the files in thepublicfolder to the output folder instead of thepublicfolder inside the output folder.new CopyWebpackPlugin({ - patterns: [{ from: Path.resolve(__dirname, '../public'), to: 'public' }], + patterns: [{ from: Path.resolve(__dirname, '../public'), to: '' }], }),
-
-
Install Tesseract.js.
npm install tesseract.js
Step 3: Build the Document Scanner Interface
-
In the HTML file, add a container for Dynamic Web TWAIN and several buttons to use it.
<h2>Web TWAIN + Tesseract OCR Demo</h2> <div class="app"> <div class="document-scanner"> <div>Document Scanner:</div> <button class="scan-btn">Scan</button> <button class="edit-btn">Edit</button> <button class="load-btn">Load Files</button> <div id="dwtcontrolcontainer"></div> </div> </div> -
In the JavaScript, initialize Dynamic Web TWAIN after the page is loaded. Here, we bind the viewer for documents to the
dwtcontrolcontainercontainer.import Dynamsoft from "dwt"; let DWObject; window.onload = function(){ initDWT(); }; function initDWT(){ const containerID = "dwtcontrolcontainer"; Dynamsoft.DWT.RegisterEvent('OnWebTwainReady', () => { DWObject = Dynamsoft.DWT.GetWebTwain(containerID); DWObject.Viewer.width = "100%"; DWObject.Viewer.height = "100%"; }); Dynamsoft.DWT.ResourcesPath = "/dwt-resources"; Dynamsoft.DWT.Containers = [{ WebTwainId: 'dwtObject', ContainerId: containerID }]; Dynamsoft.DWT.Load(); } -
Register the event for the scan button. It will show a list of scanners and let the user choose one of them to perform scanning.
document.getElementsByClassName("scan-btn")[0].addEventListener("click",function(){ if (DWObject) { DWObject.SelectSource(function () { DWObject.OpenSource(); DWObject.AcquireImage(); }, function () { console.log("SelectSource failed!"); } ); } }); -
Register the event for the load button. It allows loading local PDF and image files.
document.getElementsByClassName("load-btn")[0].addEventListener("click",function(){ if (DWObject) { DWObject.IfShowFileDialog = true; // PDF Rasterizer Addon is used here to ensure PDF support DWObject.Addon.PDF.SetResolution(200); DWObject.Addon.PDF.SetConvertMode(Dynamsoft.DWT.EnumDWT_ConvertMode.CM_RENDERALL); DWObject.LoadImageEx("", Dynamsoft.DWT.EnumDWT_ImageType.IT_ALL); } }); -
Register the event for the edit button to show an image editor.
document.getElementsByClassName("edit-btn")[0].addEventListener("click",function(){ if (DWObject) { let imageEditor = DWObject.Viewer.createImageEditor(); imageEditor.show(); } });
Screenshot of the demo:
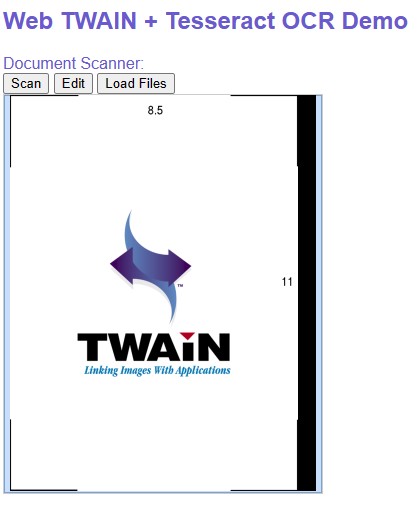
Step 4: Add Tesseract.js OCR to Extract Text
-
In the HTML file, add several elements for using Tesseract-OCR.
<div class="ocr"> <span>Tesseract:</span> <span id="status"></span> <div> <button class="ocr-btn">OCR Selected</button> <button class="batch-ocr-btn">OCR All</button> <label for="skip-processed-chk">Skip processed <input id="skip-processed-chk" type="checkbox"/> </label> <button class="download-text-btn">Download Text</button> </div> <div class="text"></div> </div> -
Initialize Tesseract-OCR after the page is loaded.
import { createWorker } from 'tesseract.js'; let worker; window.onload = function(){ initDWT(); initTesseract(); }; async function initTesseract(){ const status = document.getElementById("status"); status.innerText = "Loading tesseract core..."; worker = await createWorker({ logger: m => console.log(m) }); status.innerText = "Loading lanuage model..."; await worker.loadLanguage('eng'); status.innerText = "Initializing..."; await worker.initialize('eng'); status.innerText = "Ready"; } -
Add a function to convert one page in Dynamic Web TWAIN’s buffer to Blob for Tesseract to recognize the text in it.
async function OCROneImage(index){ return new Promise(function (resolve, reject) { if (DWObject) { const success = async (result) => { const data = await worker.recognize(result); resolve(data); }; const failure = (errorCode, errorString) => { reject(errorString); }; DWObject.ConvertToBlob([index],Dynamsoft.DWT.EnumDWT_ImageType.IT_JPG, success, failure); }else{ reject("Not initialized"); } }); } -
Register events for the
OCR Selectedbutton andOCR Allbutton. If the page has already been processed and theSkip processedcheckbox is checked, skip the page. The results are saved in theresultsDictobject with the page’s image ID as the key.let resultsDict = {}; document.getElementsByClassName("ocr-btn")[0].addEventListener("click",function(){ OCRSelected(); }); document.getElementsByClassName("batch-ocr-btn")[0].addEventListener("click",function(){ BatchOCR(); }); async function OCRSelected(){ if (DWObject && worker) { const index = DWObject.CurrentImageIndexInBuffer; const skipProcessed = document.getElementById("skip-processed-chk").checked; const ImageID = DWObject.IndexToImageID(index); if (skipProcessed) { if (resultsDict[ImageID]) { console.log("Processed"); return; } } const status = document.getElementById("status"); status.innerText = "Recognizing..."; const data = await OCROneImage(index); resultsDict[ImageID] = data; status.innerText = "Done"; showTextOfPage(ImageID); } } async function BatchOCR(){ if (DWObject && worker) { const skipProcessed = document.getElementById("skip-processed-chk").checked; const status = document.getElementById("status"); for (let index = 0; index < DWObject.HowManyImagesInBuffer; index++) { const ImageID = DWObject.IndexToImageID(index); if (skipProcessed) { if (resultsDict[ImageID]) { console.log("Processed"); continue; } } status.innerText = "Recognizing page "+(index+1)+"..."; const data = await OCROneImage(index); resultsDict[ImageID] = data; } status.innerText = "Done"; } } -
Register the
OnBufferChangedevent of Dynamic Web TWAIN. It can be triggered when the selected pages are changed. If the selected page changes, then display the extracted text of that page.DWObject.RegisterEvent('OnBufferChanged',function (bufferChangeInfo) { const selectedIds = bufferChangeInfo["selectedIds"]; if (selectedIds.length === 1) { showTextOfPage(selectedIds[0]); } }); function showTextOfPage(ImageID){ if (resultsDict[ImageID]) { const text = resultsDict[ImageID].data.text; document.getElementsByClassName("text")[0].innerText = text; }else{ document.getElementsByClassName("text")[0].innerText = ""; } } -
Add a
DownloadTextfunction to download the text file of the extracted text of the scanned pages.function DownloadText(){ if (DWObject) { let text = ""; for (let index = 0; index < DWObject.HowManyImagesInBuffer; index++) { const ImageID = DWObject.IndexToImageID(index); if (resultsDict[ImageID]) { text = text + resultsDict[ImageID].data.text; } text = text + "\n\n=== "+ "Page "+ (index+1) +" ===\n\n"; } let filename = 'text.txt'; let link = document.createElement('a'); link.style.display = 'none'; link.setAttribute('target', '_blank'); link.setAttribute('href', 'data:text/plain;charset=utf-8,' + encodeURIComponent(text)); link.setAttribute('download', filename); document.body.appendChild(link); link.click(); document.body.removeChild(link); } }
All right, we can now use Tesseract-OCR to extract the text of documents scanned with Dynamic Web TWAIN.
Screenshot of the final result:

Common Issues and Edge Cases
- Low OCR accuracy on scanned images: Tesseract performs best on clean, high-contrast images at 200 DPI or above. If text recognition is poor, use the Dynamic Web TWAIN image editor to deskew, crop, or adjust brightness/contrast before running OCR.
- Tesseract worker initialization is slow on first load: The Tesseract.js worker downloads a ~15 MB language model on first use. This is cached by the browser for subsequent loads, but the initial wait can confuse users — show a loading indicator (the demo uses the
statuselement for this). - Non-Latin languages require additional language data: The default setup loads only the English model (
eng). To OCR documents in other languages, pass the appropriate language code toloadLanguageandinitialize(e.g.,chi_simfor Simplified Chinese). Multiple languages can be loaded witheng+chi_sim.
Source Code
Check out the code of the demo to have a try: Get the complete sample project source code on GitHub