


Build Full-Text Search for Scanned Documents with JavaScript OCR and FlexSearch
Full-text search is a process of examining all of the words in every stored document to find documents meeting a certain criteria (e.g. text specified by a user).
It is possible for the full-text-search engine to directly scan the contents of the documents if the number of documents is small. However, when the number of documents to search is potentially large, we have to index the documents first to improve the efficiency. This is what most full-text search engines like Lucene, Solr and Elasticsearch do.
In the previous article, we’ve built a web application to scan documents and run OCR with Dynamic Web TWAIN and Tesseract.js. In this article, we are going to add the ability to run full-text search to it with FlexSearch.
What you’ll build: A JavaScript web app that scans physical documents with Dynamic Web TWAIN, extracts text via Tesseract.js OCR, and enables instant full-text search with match highlighting using FlexSearch.
Key Takeaways
- FlexSearch provides fast, in-browser full-text search indexing for OCR-extracted text from scanned documents.
- Dynamic Web TWAIN handles document scanning and Tesseract.js performs client-side OCR — no server-side processing is required.
- The search index can be persisted to IndexedDB using localForage, so users do not need to re-index documents on every page load.
- This approach works entirely in the browser, making it suitable for privacy-sensitive document workflows.
Common Developer Questions
How do I add full-text search to scanned documents in a JavaScript web app?
Run OCR on each scanned page, store the extracted text per page or document, and add those text bodies into a browser-side index such as FlexSearch. Once the index exists, search results can point back to the matching scanned pages immediately without rescanning or reprocessing the images.
How do I persist a FlexSearch index to IndexedDB so it survives page reloads?
The search index can be persisted to IndexedDB using localForage, so users do not need to re-index documents on every page load. We can export the index to persistent storage for future usage.
How do I highlight search matches in OCR text extracted from scanned images?
After FlexSearch returns the matching page ids, you can render the OCR text for a selected page and wrap the matched query terms with your own highlight markup. The sample does that with a regex replacement that inserts a styled span around each hit.
Prerequisites
Before you start, make sure you have:
- Node.js installed on your machine.
- A working Dynamic Web TWAIN project from the previous OCR tutorial.
- Get a 30-day free trial license for Dynamic Web TWAIN.
Step 1: Install FlexSearch and LocalForage
-
Install FlexSearch.
npm install flexsearch -
Install
localForageto save index to IndexedDB.npm install localForage
Step 2: Create a Full-Text Search Index from OCR Results
The OCR results of document pages are saved using localForage with keys like the following, where timestamp is used as the ID of documents:
timestamp+"-OCR-Data"
The content of the OCR data is an object containing the OCR results produced by Tesseract with the document index as the key.
{
"0": {
"jobId": "Job-3-86bc4",
"data": {
"text": "| 8.5\ni ‘ 11\nTWAIN\nLinking Images With Applications\n"
}
}
}
We can create an index from the OCR results with the following code:
import { Index } from "flexsearch";
const documentIndex = new Index();
const keys = await localForage.keys();
const document = [];
for (const key of keys) {
if (key.indexOf("OCR-Data") != -1) { //OCR results stored as timestamp+"-OCR-Data"
const resultsDict = await localForage.getItem(key);
const timestamp = key.split("-")[0];
const pageIndices = Object.keys(resultsDict);
for (const i of pageIndices) {
const result = resultsDict[i];
if (result) {
const id = timestamp+"-"+i;
document.push({id:id,body:result.data.text}); //push document pages to an array first
}
}
}
}
document.forEach(({ id, body }) => {
if (id in Object.keys(documentIndex.register)) {
documentIndex.remove(id); // remove previously added document pages
}
documentIndex.add(id, body); //add document pages to index
});
Step 3: Perform Full-Text Search and Highlight Matches
Next, we can perform full-text search using the index created.
const query = "remote scan";
const results = documentIndex.search(query);
console.log(results); // output the IDs of document pages found.
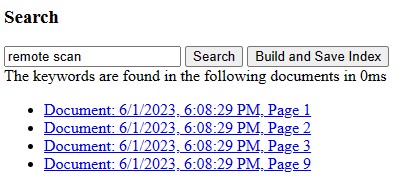
We can highlight all the matches with a yellow background. FlexSearch does not support this by default. We have to do this ourselves.
function highlightQuery(query){
let content = document.getElementsByClassName("text")[0].innerHTML;
// Build regex
const regexForContent = new RegExp(query, 'gi');
// Replace content where regex matches
content = content.replace(regexForContent, "<span class='hightlighted'>$&</span>");
document.getElementsByClassName("text")[0].innerHTML = content;
}

Step 4: Export and Import the Search Index for Persistence
We can export the index to persistent storage for future usage.
-
Export and save the index to IndexedDB.
let indexStore = localForage.createInstance({ name: "index" }); function SaveIndexToIndexedDB(){ return new Promise(function(resolve){ documentIndex.export(async function(key, data){ // do the saving as async await indexStore.setItem(key, data); resolve(); }); }); } -
Import the index from IndexedDB.
async function LoadIndexFromIndexedDB(){ const keys = await indexStore.keys(); for (const key of keys) { const content = await indexStore.getItem(key); documentIndex.import(key, content); } }
Common Issues and Edge Cases
- OCR accuracy affects search quality. If Tesseract.js produces garbled text from low-resolution scans, FlexSearch will index that noise. Scan at 300 DPI or higher for reliable OCR output.
- FlexSearch
importrequires matching configuration. When importing a previously exported index, the FlexSearchIndexinstance must be created with the same options used during export. A mismatch silently produces empty search results. - Large indexes can slow IndexedDB writes. For document sets exceeding a few hundred pages, consider throttling exports or batching
setItemcalls to avoid blocking the UI thread.
Source Code
Check out the code of the demo to have a try: Get the complete sample project source code on GitHub