Dynamsoft Developer Blog
Featured Content
View More >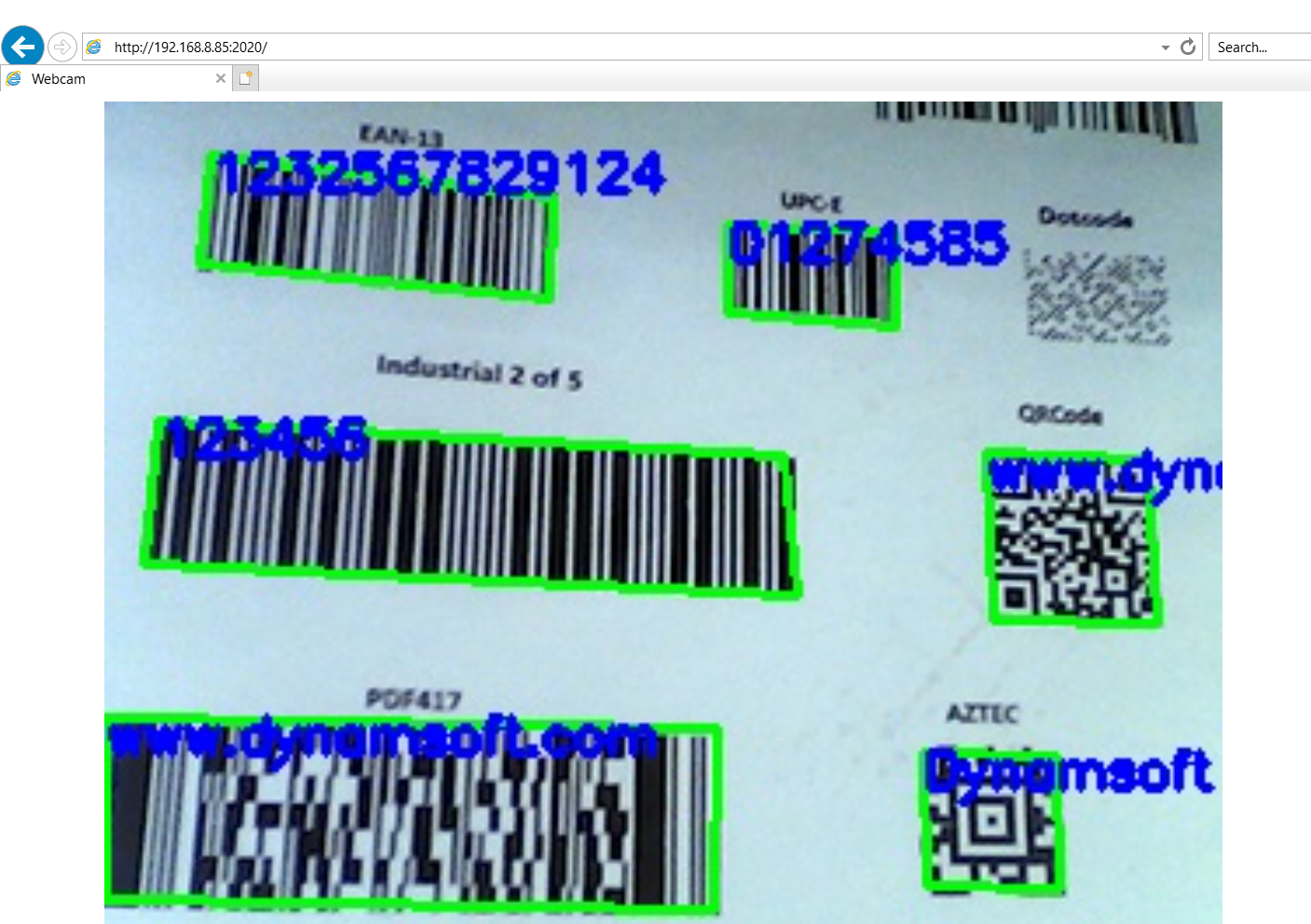
Building a Real-Time Barcode QR Code Scanner with Node.js for Desktop and Web
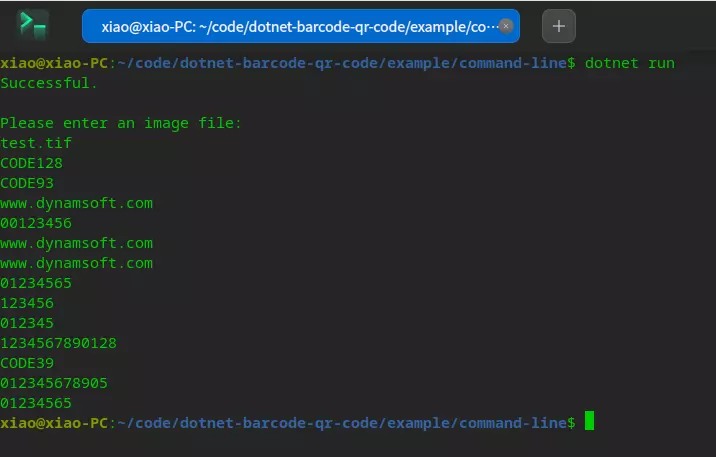
How to Build .NET 6 Barcode and QR Code SDK for Windows, Linux & macOS
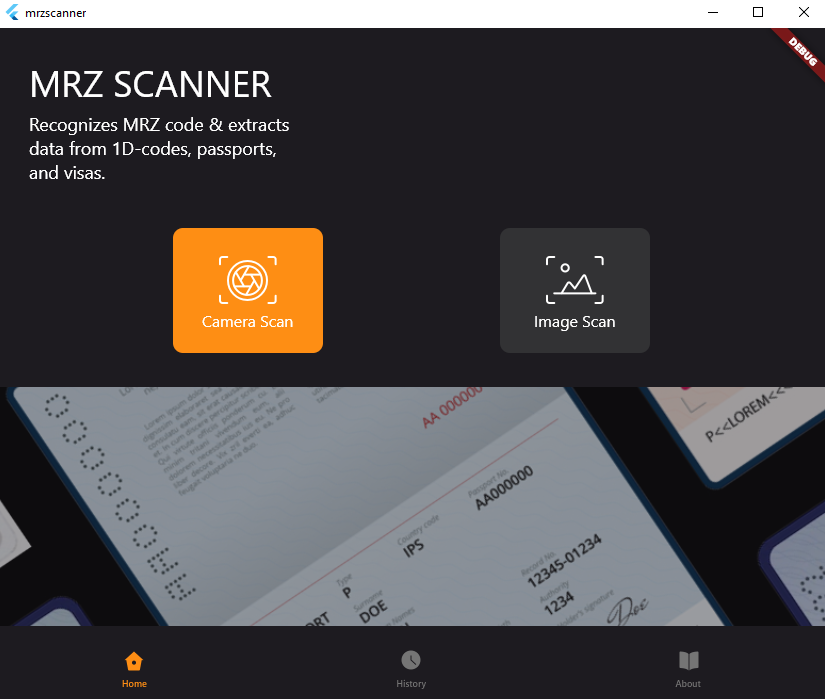
How to Create a Cross-platform MRZ Scanner App Using Flutter and Dynamsoft Label Recognizer
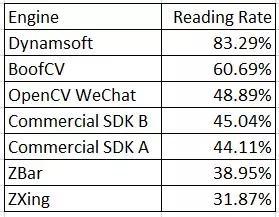
QR Code Reading Benchmark and Comparison
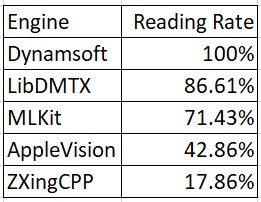
What are the Best Data Matrix Reading SDKs?
-
When digitizing documents, we may accidentally scan a document image twice. Finding the duplicate images manually is painstaking. In this article, we are going to use JavaScript to detect duplicate document images automatically. How to Calculate the Similarity between Two Images We need to compare two images to check whether...
-
Many open-source JavaScript libraries for reading barcodes and QR codes exist, yet few are suited for enterprise use due to a lack of long-term updates and maintenance roadmaps. Additionally, the performance of pure JavaScript often falls short. For those prioritizing performance, WebAssembly serves as a superior alternative to pure JavaScript...
-
Starting from version 18.0, the Dynamic Web TWAIN SDK has expanded its support for the eSCL protocol. This enhancement enables the SDK to support not only USB-connected scanners but also network scanners. Furthermore, Dynamsoft has released an Android app for eSCL communication, benefiting both Android and Chromebook users. This breakthrough...
-
Node.js, Express, and Jade are technologies often used together to build web applications. Node.js runs the server, handling HTTP requests and responses. Express is used to simplify the routing and middleware setup, managing everything from routes to handling requests and views. Jade is used as the templating engine within Express....
-
An identity document or ID card is any document that may be used to prove a person’s identity. There are various forms of identity documents: driver’s license, passport and formal identity card. Barcodes and MRZ (machine-readable zones) are often printed on an ID card so that its info can be...
-
If you want to use the PHP Laravel framework to build a web-based barcode and QR code reader, you can implement the barcode detection logic on either the client side or the server side. Dynamsoft offers a variety of SDKs for different platforms, including desktop, mobile, and web. In this...
-
When using PHP, you may sometimes need to integrate a few C++ libraries. This article guides you through the process of building a PHP Barcode and QR Code reading extension using the Dynamsoft C++ Barcode SDK on both Windows and Linux. This article is Part 1 in a 2-Part Series....
-
Shadow DOM is a web standard designed to encapsulate HTML and CSS into web components. It allows for the creation of separate DOM trees and specifies how these trees interact with each other in a document. Polymer is a library developed by Google to make it easier to create reusable...
-
Laravel is a PHP Framework. This article shares how to use Dynamic Web TWAIN to scan and upload documents in a Laravel project, enhancing web document management capabilities. This article is Part 5 in a 5-Part Series. Part 1 - Building Web Document Scanning Applications with ASP.NET Core MVC Part...
-
An identity document or ID card is any document that may be used to prove a person’s identity. There are various forms of identity documents: driver’s license, passport and formal identity card. Barcodes and MRZ (machine-readable zones) are often printed on an ID card so that its info can be...