



Localize and Extract Key Data from Specified Region using OCR

Enterprise-Ready Text Detection and Recognition SDK
Dynamsoft Label Recognizer SDK uses OCR to read alphanumeric characters and standard symbols from images with varying background colours, fonts, or text sizes. Unlike traditional OCR, our label recognizer is designed to parse text that does not follow natural language rules. Dynamsoft Label Recognizer can be customized for specific character and symbol patterns such as ID cards, inventory labels, price tags and automotive VIN codes.

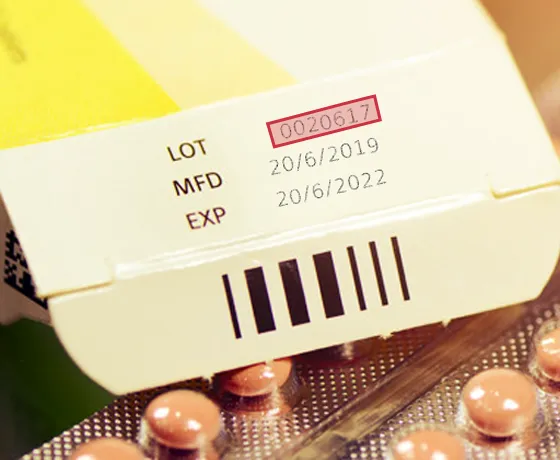
Lot No. on Drug Bottles in Healthcare
Incorporating data capture and text recognition technologies into healthcare software adds remarkable value to their applications.

Parcel Labels in Transport and Logistics
OCR technology helps in reducing the errors, energy, and time associated with manual data entry processes in the transport and logistics industries.

Automatic Data Extraction
Businesses can boost productivity with OCR, enabling fast, accurate data retrieval and automated sorting for streamlined document management.

Inventory and Warehouse Management
Enable warehouse staff to scan inventory even without barcodes, ensuring accurate tracking and restocking.

VIN Scanning (beta release)
Advanced text recognition technology is essential in the automotive industry, enabling fast and accurate VIN scanning from various angles and distances.

Retail (beta release)
Ensure accurate price labels, reducing errors and improving customer service by allowing employees to verify prices even if barcodes are damaged.

Parts Tracking and Maintenance (beta release)
Enable maintenance operators to efficiently track parts in a warehouse, reduce costs by replacing dedicated scanners with smart devices, and improve accuracy in identifying serial numbers and labels.

Voucher Code Scanning (beta release)
Allow customers to scan voucher codes on gift cards using their mobile phones, enhancing engagement by integrating serial number scanning into an app or website.

Checks in Banking (beta release)
Streamline banking by enabling easy check deposits and fast check processing.
Sparse and short text, sometimes random numbers and chars for machines to read
Dense text, mostly natural language
Images such as pricing labels, ID cards, tags
Full-page documents
Extract meaningful data that are structured and semi-structured
Convert image to text for archive and search
Use reference regions to locate the meaningful text, such as, below a barcode, or, within a yellow rectangle
All texts in the doc are of interest
Customized regex to ensure accuracy
Grammatically interprets and analyzes phrases by using a dictionary to improve accuracy
Get more out of your images
Discover the features available in Dynamsoft Label Recognizer SDK to take control of your data.
Extract and Recognize Characters from Various Image Formats
- Dynamsoft Label Recognizer is capable of reading of alphanumeric characters and standard symbols, including period, commas, and dashes, of varying colours, font sizes and styles.
- Supported image formats include BMP, TIFF, JPEG, PNG and PDF.

 Specify an Area to OCR Text Using a Reference Region
Specify an Area to OCR Text Using a Reference Region
- Dynamsoft Label Recognizer does not have to recognize texts from a full-sized image. Users have the option to run a zonal OCR feature for a text area. The OCR SDK allows you to specify the relative position of texts to a reference region.
- For example, a tag in a warehouse, where the texts of interest are always on the left and right of a barcode. The coordinates of the barcode can be used to specify the relative position of the text areas. Being able to specify this is useful because it further speeds scan recognition and improves recognition accuracy.
- Another example would be a price tag, where the text of interest is always on a yellow square background. In this case, the yellow square can serve as the reference region.


 Use a Regular Expression to Improve Accuracy and Robustness
Use a Regular Expression to Improve Accuracy and Robustness
- Developers can also specify a Regular Expression to indicate to Dynamsoft Label Recognizer the assumption about the texts. For example, an automotive VIN has a fixed number of digits and each digit has certain values to choose from. While Dynamsoft Label Recognizer can usually scan all digits correctly as is, some challenging environments might pose obstacles. So, the semantics of a Regular Expression, to specify alphanumeric values that are expected to be scanned, can give Dynamsoft Label Recognizer more context for better OCR results.
- After OCR finishes, a Regular Expression can also be used to verify and filter out texts that are not of interest. Developers can also use a character model to restrict alphanumeric or symbol possibilities. For example, you might specify numbers only, a mix of numbers and letters, specific fonts, special characters, and so on.
 Sophisticated Image Pre-Processing Algorithms
Sophisticated Image Pre-Processing Algorithms
- For images of poor quality, sophisticated algorithms built into Dynamsoft Label Recognizer SDK are applied to improve contrast, remove noise, and so on. The characteristics of texts can also be used to improve the image quality. For example, with the algorithms the curve of the text can be used to correct distorted images.

 Stitch Content Results from Neighboring Video Frames
Stitch Content Results from Neighboring Video Frames
- Dynamsoft Label Recognizer SDK supports reading content from video streams. For a specified frame, the SDK extracts texts using OCR and cross references the result with neighbor frames for verifiable accuracy. The SDK can also intelligently decide if the text results are a partial or full match and overlap the partial results from sequential frames together.

Try the Software Development Kit (SDK) for Free
Dynamsoft Label Recognizer is now integrated into the Dynamsoft Capture Vision suite, with its functionalities available through the Capture Vision installers.