


Scan Barcode and QR Code From Different PDF Types
PDF files can be broadly categorized into three types based on how they are created:
- Digitally Created PDFs (True PDFs)
- Image-only PDFs
- Image-over-Text PDFs (Searchable PDFs)
Different PDF structures require different processing strategies to achieve optimal barcode recognition performance. Dynamsoft Barcode Reader includes a built-in PDF rendering engine designed specifically for barcode recognition.
In this article, we’ll explore how Dynamsoft Barcode Reader decodes barcodes and QR codes from different PDF types and how its PDF processing engine automatically optimizes barcode extraction for speed and accuracy.

1. Scan Barcodes and QR Codes from a Digitally Created PDF
Digitally created PDFs, often referred to as True PDFs, contain text and graphics that are generated directly by software applications such as Microsoft® Word®, Excel®, or virtual printers. Barcodes in these PDFs are typically stored as either vector graphics or raster images.
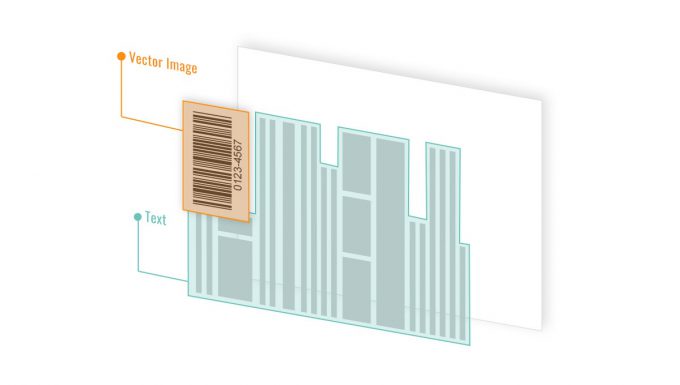
1.1 Barcodes Stored as Vector Graphics
Vector-based PDFs present a unique opportunity for performance optimization.
Most barcode SDKs first render an entire PDF page into a bitmap image and then perform barcode localization and decoding on the rendered image. This rendering step can significantly increase processing time.
Dynamsoft Barcode Reader takes a different approach. Instead of rendering the page, it directly analyzes the PDF’s vector content to locate and decode barcode regions. Eliminating the rendering step reduces processing overhead while preserving barcode fidelity.
C# Example
PublicRuntimeSettings settings = reader.GetRuntimeSettings();
settings.PDFReadingMode = EnumPDFReadingMode.PDFRM_VECTOR;
reader.UpdateRuntimeSettings(settings);
Performance Comparison
To evaluate performance, we compared Dynamsoft Barcode Reader against two leading commercial barcode SDKs using the same PDF file.
| File 1 (download the sample file) | |
| Commercial SDK 1 | Found 3 barcodes in 1501 ms |
| Commercial SDK 2 | Found 3 barcodes in 605 ms |
| Dynamsoft (Vector Mode) | Found 3 barcodes in 4 ms |
In this benchmark, Dynamsoft Barcode Reader completed decoding approximately 100× faster than the other SDKs tested. Similar results were observed across multiple vector-based PDF samples.
Note:
PDFRM_VECTORcurrently supports linear barcodes only.
1.2 Barcodes Stored as Raster Images
In many digitally created PDFs, barcodes are embedded as raster images such as PNG, JPEG, or BMP files.
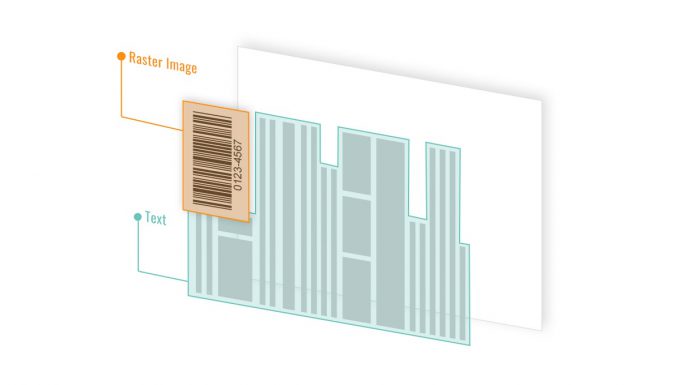
Starting with the upcoming Dynamsoft Barcode Reader v11.6, raster images can be extracted directly from PDF files and passed to the barcode engine for decoding. This eliminates the need to render the entire PDF page before barcode recognition.
By processing only the embedded image objects that contain barcode data, the SDK reduces unnecessary rendering overhead and improves decoding efficiency. Compared to full-page rendering, direct image extraction requires less processing time and memory while maintaining high decoding accuracy.
2. Scan Barcodes and QR Codes from Scanned and Searchable PDFs
Image-only PDFs are commonly generated by scanners, multifunction printers (MFPs), and camera captures. Since the entire page is stored as an image, barcode recognition works similarly to scanning a standard image file.
The PDF engine first extracts each page and converts it into an image that can be processed by the barcode reader.
3. Barcode Scanning from Image-over-Text PDFs
Image-over-text PDFs, also known as searchable PDFs, are created by applying OCR to scanned documents. In these files, the recognized text is stored separately behind the page image. The barcode itself remains part of the image layer.
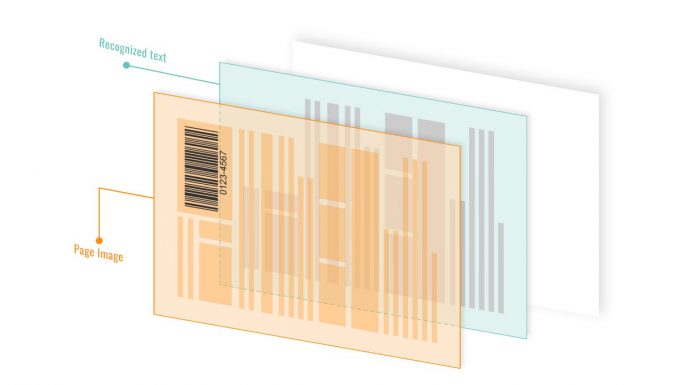
Because the image and OCR text are stored independently, barcode recognition can focus entirely on the page image while ignoring the text layer. This enables the same barcode-reading workflow used for image-only PDFs.
Intelligent PDF Processing with PDFRM_MULTIMODAL
Dynamsoft Barcode Reader v11.6 introduces PDFRM_MULTIMODAL as the default PDF processing mode. Rather than relying on a single extraction strategy, the engine analyzes the structure of each PDF and automatically selects the most efficient method for accessing barcode content.
Depending on the document, the SDK may:
- Extract vector graphics directly for barcode localization and decoding
- Extract embedded raster images without rendering the entire page
- Process scanned page images when image-based decoding is required
For most applications, no manual configuration is necessary. The SDK automatically chooses the optimal workflow to balance speed, resource usage, and decoding accuracy.
Advanced users can still override the default behavior through the PDFReadingMode parameter when working with specialized document types or performance-tuning scenarios.
About Dynamsoft Barcode Reader
Dynamsoft Barcode Reader enables developers to add 1D and 2D barcode recognition to desktop, mobile, web, and server applications.
Supported programming languages include C#, VB.NET, Java, C++, Python, C, Android Java, Swift, Kotlin, and JavaScript.
Key Takeaways
- Automatic PDF Optimization:
PDFRM_MULTIMODALanalyzes each PDF and automatically selects the most efficient barcode extraction strategy. - Vector-Based Processing Delivers Maximum Speed: Direct vector extraction can dramatically reduce processing time for digitally generated PDFs.
- Comprehensive PDF Support: Dynamsoft Barcode Reader supports digitally created, scanned, and searchable PDFs.
- Efficient Raster Image Extraction: Embedded barcode images can be extracted directly without rendering the entire page.
- Try It Yourself: Download and experiment with the 30-day trial. dynamsoft.com/barcode-reader/downloads/