


Tag: ocr
-

The Machine Readable Zone (MRZ) is the section of passports and IDs designed for automated reading. Despite its restricted character set (A–Z, 0–9, <), reliable recognition is not always straightforward in practice. Common challenges include: Character confusables such as 0 vs. O, 1 vs. I, and 5 vs. S. Image...
Read more › -
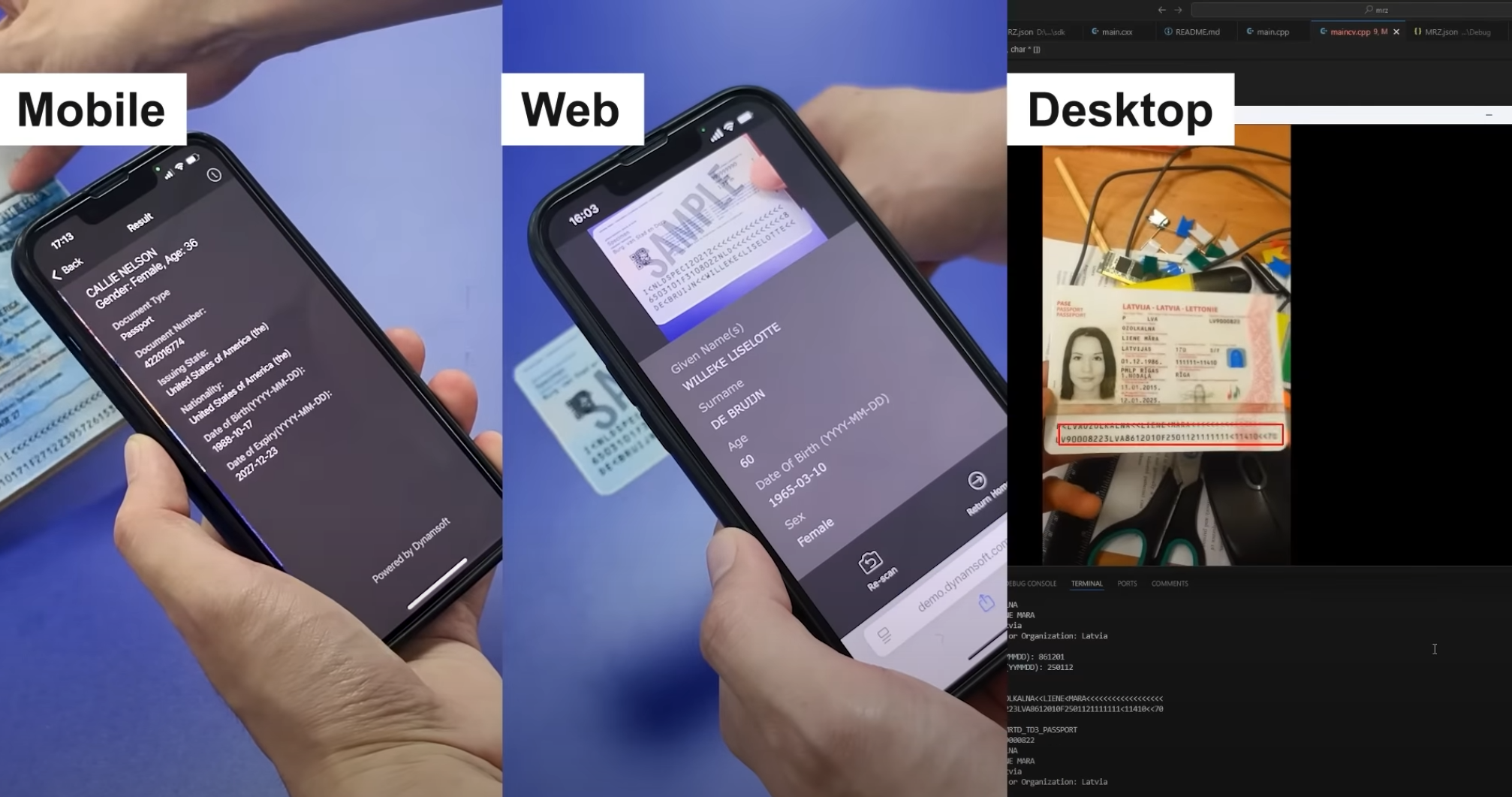
In industries like travel, banking, and government services, accuracy in identity document scanning isn’t optional — it’s mission-critical. A single misread can mean a delayed boarding gate, a failed KYC onboarding, or a compliance red flag. That’s where the Dynamsoft MRZ Scanner SDK comes in. Built on our years of...
Read more › -

DotCode cigarette tracking plays a critical role in modern tobacco track and trace systems by enabling accurate unit-level traceability from cartons down to individual packs. By decoding high-density DotCode symbols printed on cigarette packaging, manufacturers and regulators can ensure compliance, prevent counterfeiting, and monitor supply chains in real time. Using...
Read more › -

The global shipping industry is essential to international commerce, with over 90% of commodities globally transported by sea. The capacity to accurately monitor and control the movement of these containers is essential for maintaining efficient supply chains. The manual input of container numbers, a critical component of this procedure, presents...
Read more › -

Effective vendor management in today’s dynamic business landscape often involves handling large volumes of physical documents, which poses a significant challenge. Extracting key details like vendor names, numbers, and other critical information manually is time-consuming, error-prone, and reduces overall efficiency. To tackle these challenges, organizations are progressively adopting automation solutions....
Read more › -

We have been cultivating a long-time interest in the field of optical character recognition (OCR). Today, we are excited to announce Dynamsoft Label Recognizer 2.0, which is revolutionary to version 1.0 in its ability to detect and recognize text in images. Highlighted Features Dynamsoft Label Recognizer 2.0 integrates OpenCV DNN...
Read more › -

Optical Character Recognition (OCR) helps users capture and recognize text information from images. However, basic OCR technology cannot meet the growing requirement for data control, meaning that in some complex scenarios, we may need to extract critical data from a specified region. Dynamsoft has developed some new extraction technologies powered...
Read more › -

OCR (Optical Character Recognition) is a technology used by computers to convert text in images into editable and searchable text data. It is implemented using pattern recognition and artificial intelligence. OCR is widely used for document recovery, data entry, accessibility, and various business applications. It eliminates the need for manual...
Read more › -
Optical Character Recognition (OCR) technology is a mature technology with widespread business use. Essentially, it enables users to extract text from an image so it can be manipulated in a word processor or database. In other words, it transforms a difficult-to-use image into meaningful content. So, what are some of...
Read more › -

Business productivity decreases when paper starts stacking up in the office, making it impossible to have an office workspace without a document scanner. Millions of paper documents are scanned daily to find, store, verify, and share information. This digital transit of documents requires fast and accurate OCR functionality working at...
Read more ›