


Build a Python Barcode Scanner with Tesseract OCR Fallback for Damaged Images
When scanning barcodes in production (warehouse, logistics, healthcare, retail), image quality issues like blur, motion, glare, low contrast, or physical damage can cause even strong barcode algorithms to fail. Fortunately, most linear (1D) barcodes also include human-readable text. That text becomes a powerful assist layer: if the barcode fails, OCR (Optical Character Recognition) can still recover the payload — or help validate borderline reads.
This tutorial shows how to pair two complementary technologies:
- Dynamsoft Barcode Reader – robust, high-speed, localization‑aware barcode decoding.
- Tesseract OCR – open-source OCR used here as a fallback / verification tool for damaged or low-quality images that cannot be decoded by barcode SDK.
Instead of treating OCR as a replacement (it is slower and less structured), we treat it as a confidence booster and resilience mechanism.
What you’ll build: A Python script that decodes 1D barcodes using Dynamsoft Barcode Reader and automatically falls back to Tesseract OCR to extract digit data when barcode decoding fails on damaged or low-quality images.
Key Takeaways
- Dynamsoft Barcode Reader handles high-speed, localization-aware barcode decoding while Tesseract OCR serves as a fallback layer for images where the barcode structure is too damaged to decode.
- The
CaptureVisionRouter.capture()method decodes barcodes from a file path in a single call, returning format, text, and bounding-box coordinates. - Tesseract OCR works best as a cross-validation tool for 1D barcodes, not a primary decoder — it is slower and cannot infer barcode structure or checksum.
- This pattern is applicable in warehouse, logistics, healthcare, and retail workflows where image quality is inconsistent.
Common Developer Questions
How do I read barcodes with Tesseract OCR in Python?
Use a barcode SDK as the primary decoder, then call Tesseract on the same image only when the barcode read fails or needs verification against printed digits. In this article, Tesseract is treated as a fallback for damaged 1D barcode images rather than as the main barcode reader.
How can I improve barcode recognition accuracy for damaged or blurry images in Python?
Add a second recovery path that extracts the human-readable digits with OCR when the bars themselves are too damaged or blurred to decode reliably. This fallback is especially useful for 1D codes where the printed digits are still legible even when the barcode structure is degraded.
What is the best Python barcode scanning library for production use?
For production, the important distinction is between a real barcode decoder and a generic OCR engine. This tutorial uses Dynamsoft Barcode Reader as the primary production scanner and positions Tesseract only as a fallback or validation layer for difficult 1D images.
Prerequisites
- Get a free trial (30 days) for Dynamsoft Barcode Reader
- Python 3.8+
- Install Tesseract OCR:
- Windows: Install UB Mannheim build; ensure
C:\\Program Files\\Tesseract-OCRis on PATH -
macOS:
brew install tesseract - Linux:
sudo apt update sudo apt install tesseract-ocr -y sudo apt install libtesseract-dev -y
- Windows: Install UB Mannheim build; ensure
-
Python dependencies:
pip install dynamsoft-capture-vision-bundle pytesseract pillow
Prepare Test Images for Barcode and OCR Validation
The project includes two test images:
-
codabar.jpg- A clear Codabar barcode image
-
damaged.png- A damaged barcode image to demonstrate OCR fallback
Step 1: Decode Barcodes and Validate Results with Tesseract OCR
Below is the core script app.py. It:
- Initializes the Dynamsoft license.
- Repeatedly accepts an image path.
- Attempts barcode decoding.
- Always performs OCR digit extraction.
- Prints both results so you can compare and validate.
from PIL import Image
import pytesseract
import os
import sys
from dynamsoft_capture_vision_bundle import LicenseManager, EnumErrorCode, CaptureVisionRouter, EnumPresetTemplate
def main():
print("**********************************************************")
print("Welcome to Dynamsoft Barcode Reader")
print("**********************************************************")
error_code, error_message = LicenseManager.init_license(
"LICENSE-KEY")
if error_code != EnumErrorCode.EC_OK and error_code != EnumErrorCode.EC_LICENSE_CACHE_USED:
print("License initialization failed: ErrorCode:",
error_code, ", ErrorString:", error_message)
else:
cvr_instance = CaptureVisionRouter()
while (True):
image_path = input(
">> Input your image full path:\n"
">> 'Enter' for sample image or 'Q'/'q' to quit\n"
).strip('\'"')
if image_path.lower() == "q":
sys.exit(0)
if image_path == "":
image_path = "codabar.jpg"
if not os.path.exists(image_path):
print("The image path does not exist.")
continue
result = cvr_instance.capture(
image_path, EnumPresetTemplate.PT_READ_BARCODES.value)
if result.get_error_code() != EnumErrorCode.EC_OK:
print("Error:", result.get_error_code(),
result.get_error_string())
else:
items = result.get_items()
print('Found {} barcodes.'.format(len(items)))
for item in items:
format_type = item.get_format_string()
text = item.get_text()
print("Barcode Format:", format_type)
print("Barcode Text:", text)
location = item.get_location()
x1 = location.points[0].x
y1 = location.points[0].y
x2 = location.points[1].x
y2 = location.points[1].y
x3 = location.points[2].x
y3 = location.points[2].y
x4 = location.points[3].x
y4 = location.points[3].y
print("Location Points:")
print("({}, {})".format(x1, y1))
print("({}, {})".format(x2, y2))
print("({}, {})".format(x3, y3))
print("({}, {})".format(x4, y4))
print("-------------------------------------------------")
## Inovke Tesseract OCR
result = pytesseract.image_to_string(Image.open(image_path))
digits = ''
for i in result:
if ord(i) >= 48 and ord(i) <= 57:
digits += i
print(f'OCR Result: {digits}')
if __name__ == "__main__":
main()
You must replace LICENSE-KEY with your own.
Step 2: Run the Application and Verify OCR Fallback on Sample Images
-
codabar.jpg
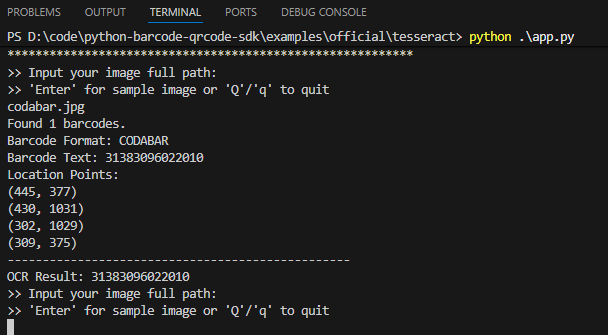
-
damaged.png
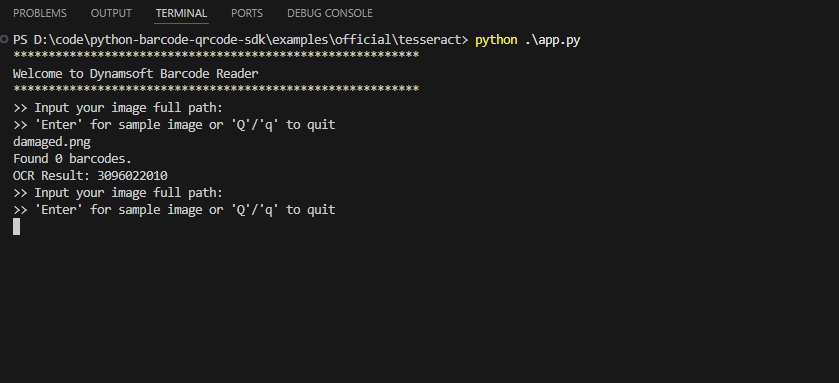
When to Use Tesseract OCR vs. a Dedicated Barcode SDK
Understanding when each tool excels helps you build a more robust pipeline:
| Feature | Tesseract OCR | Dynamsoft Barcode Reader |
|---|---|---|
| Barcode structure awareness | No | Yes (localization + checksum) |
| 1D barcode formats supported | Limited (reads visible text only) | 20+ formats |
| Speed (typical) | 100–500 ms/image | < 50 ms/image |
| Damaged image handling | Partial | High (dewarping, noise tolerance) |
| Python package | pytesseract |
dynamsoft-capture-vision-bundle |
| License | Open-source (Apache 2.0) | Commercial (free 30-day trial) |
Use Tesseract as a fallback or cross-validation layer when barcode libraries fail due to physical damage. Do not use Tesseract as a primary barcode decoder — it cannot validate checksum digits, infer format type, or handle 2D codes.
Common Issues & Edge Cases
- Tesseract returns empty or garbled text on barcode images: Tesseract is not trained on barcode fonts. Pre-process the image (grayscale, thresholding, DPI upscaling to ≥ 300 DPI) before calling
pytesseract.image_to_string(). For 1D barcodes, restrict to digits:pytesseract.image_to_string(img, config='--psm 7 -c tessedit_char_whitelist=0123456789'). TesseractNotFoundErroron Windows: Tesseract must be on the system PATH. If installed to the default location, add it manually or setpytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'at the top of your script.- Dynamsoft license initialization fails with
EC_LICENSE_INVALID: The 30-day trial license is tied to the machine UUID. Ensure you activated the key on the Dynamsoft customer portal and thatLicenseManager.init_license()is called before creating theCaptureVisionRouterinstance.